

Last year, agents finally got a standard way to use tools. MCP caught on fast because it solved something tedious and real: Every tool spoke its own dialect, and nobody wants to maintain the same integration 10 times over. Learning never got that treatment. An agent can call a tool, but there’s still no shared way for it to practice and get better at the actual job. OpenEnv goes after that gap, which is at least as big as the one MCP closed.
Jay Parikh made the case that what moves your business is the system around the model, not the model by itself. Satya Nadella put a finer point on it: The asset you keep isn’t the model you rent; it is the learning loop you own. That can land like a slogan, so here is the concrete version: The loop is an environment where your agent does the real work, a rubric that scores the outcome you actually care about instead of some proxy, rollouts you can repeat, and a way to turn those scores into a better agent. That part compounds. The model in the middle is the easy thing to swap.
“The winners won’t be those with the most demos, but those that turn AI into a governed, continuously improving system for running real work.”
What you can’t just swap out is the rest of the loop, and its hard part is turning a score into a better agent. There are two ways to do that. One leaves the weights alone and reworks everything around the model: the prompt, the tools, the skills. The other retrains the model itself. Make a change either way, keep it only if it wins on tasks the agent hasn’t seen, and send that version back in. Each lap starts higher than the last. That is the hill-climbing loop, and the diagram below puts it on one page.
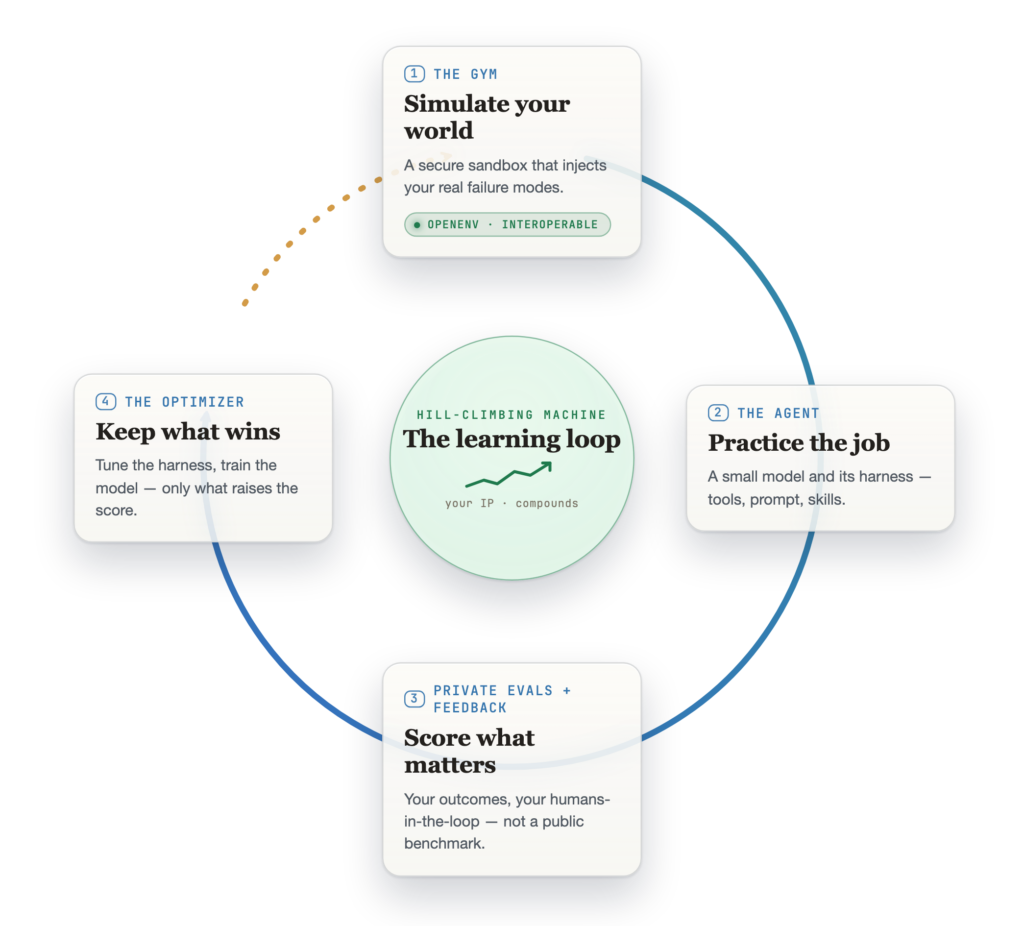
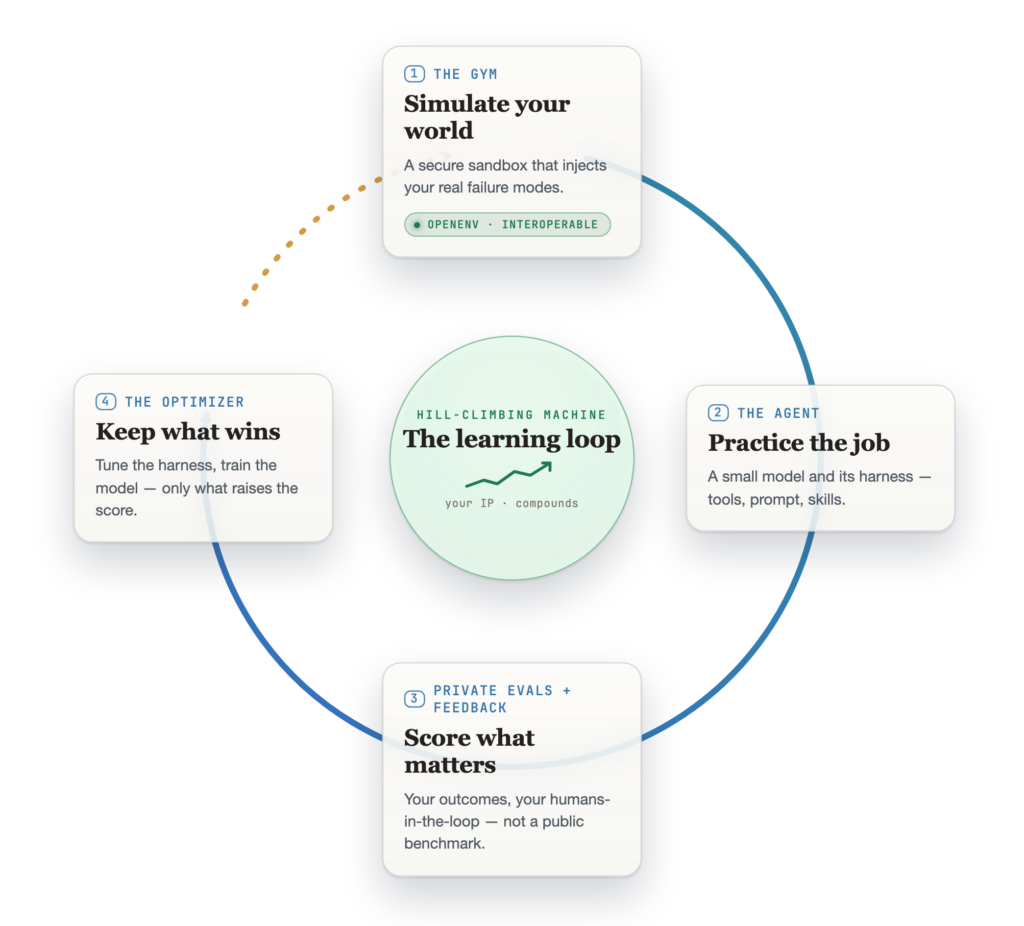
The hill-climbing loop. The full walkthrough, including the non-parametric vs. parametric split, is in the companion post on the Microsoft Foundry blog.
An environment is not a test harness
Most teams treat an environment as a test: Run the agent, read a score, move on. That undersells it. Codify the outcome you actually want, as a rubric, along with the workflow, the tools, and the constraints, and the environment stops being a test and becomes a learning system: The agent practices in it, gets scored against that outcome, and gets better with every run. What stands in the way is rarely the idea. It is the plumbing. Every trainer, runtime, and model expects the environment in a different shape, so every pairing becomes its own integration. OpenEnv removes that tax. One small contract (reset, step, state) gives the whole stack three properties it never had: open, because the standard is community-built; interoperable, because any model, trainer, or runtime can speak it; and modular, because you can swap any one of them without rebuilding the environment.
OpenEnv can become for agent learning what MCP became for tools and context.
So here is the claim, stated plainly: OpenEnv can become for agent learning what MCP became for tools and context. That’s a strong claim. It is also the right one, because it makes the environment, not the vendor, the unit of reuse. That’s why Microsoft joined OpenEnv alongside Hugging Face, Meta’s PyTorch team, NVIDIA, Prime Intellect, Unsloth, Modal, and others. OpenEnv isn’t a framework. It’s a protocol.

What it unlocks is ownership: private environments, private evals, repeatable rollouts, secure sandboxes, and optimization that isn’t married to one model or trainer. You stop calling a frontier model and hoping. You start owning the loop that makes an agent better at your work, and you keep that loop when the model underneath it changes.
The protocol only stays relevant if it absorbs the frontier
An open standard earns its place by pulling in research, not by sitting still. The clearest example we have shipped is a PR: ECHO world-modeling, landed as RFC 010, which brings a Microsoft Research result, “Terminal Agents Learn World Models for Free,” into OpenEnv where any team can use it (microsoft/echo-rl). A lab technique becomes a shared capability. That is how the loop gets democratized.
Here’s what it does: An agent transcript is half actions (what the model writes) and half observations (what the environment writes back). Standard agent-RL trains the actions and throws the observations away. ECHO keeps them: a small cross-entropy term that makes the policy predict the environment’s own tokens, a world model, from logits it already computed in the same forward pass. No extra rollouts, no teacher, no labels.
L = L_GRPO(action tokens) + λ · CrossEntropy(observation tokens)

ECHO in one step. One rollout, split by per-token role: Actions get the RL loss, observations get a λ-weighted cross-entropy loss, summed into a single optimizer step. λ = 0 is vanilla RL, so it is safe to adopt incrementally.
The discarded signal isn’t a rounding error. On a captured agent episode, 4,659 of 5,247 learnable tokens, 89%, are environment observations, 7.9 times the action tokens. Prime Intellect reaches the same place in “True Agents Model the World,” restating supervised learning on tool-response tokens as RL with a constant positive advantage, foldable in at no extra cost. Two groups, one direction: World-modeling belongs inside the RL loop, not bolted on afterward.
The honest version of the result is about generalization, not a magic number. With λ on versus off, training reward barely moves; held-out performance is where ECHO pulls ahead. Its published results: held-out pass@1 roughly doubles on TerminalBench-2.0, RL reaches its target about 2.3× faster, and it recovers 50% to 104% of expert-SFT with no teacher. Keep λ small and sweep it; the dense signal overfits if you push it.

What the weight update buys. Same training reward; held-out pass@1 roughly doubles. ECHO also reports about 2.3× faster RL and 50% to 104% of expert-SFT recovered with no teacher (arXiv 2605.24517, microsoft/echo-rl on SkyRL; corroborated by Prime Intellect).
You can watch it on a laptop in about 40 seconds. A small model on a deterministic toy terminal env drives held-out env-token cross-entropy toward zero. It reaches zero only because that toy world is fully predictable; a real environment keeps its irreducible entropy (near 4.4 nats), so ECHO sharpens predictions rather than perfecting them. The repo is open: OpenEnv, examples/echo_world_model, python train_echo.py --steps 60 --seed 0.
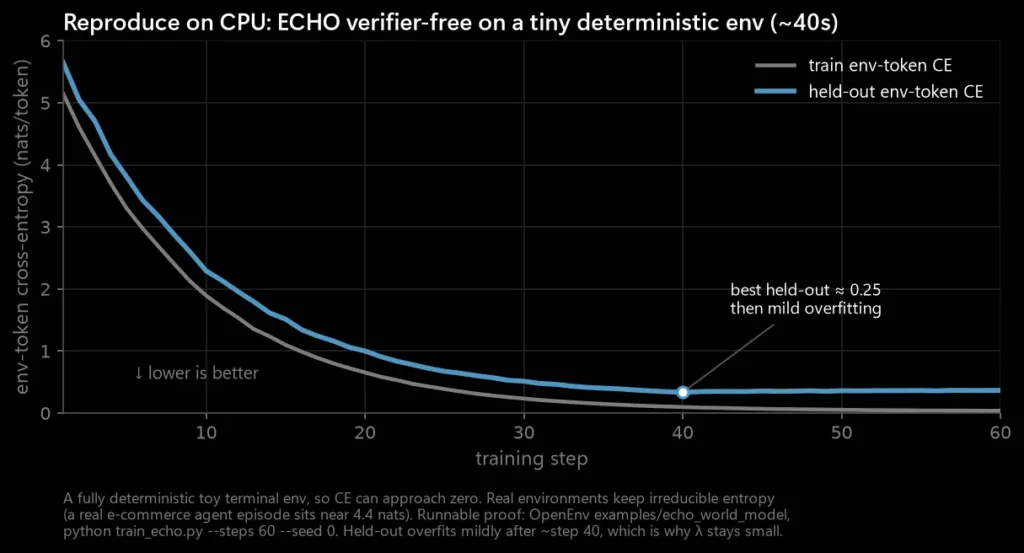
Reproduce it on CPU. A toy, fully deterministic terminal env, so cross-entropy can approach zero; a real env keeps its irreducible entropy instead. The held-out line bottoms near step 40 and then mildly overfits, which is why λ stays small.
And it survives the jump from a laptop to real training. Because supervised learning on the observation tokens is just RL with a constant positive advantage, there is no second loss function: You reuse the same forward_backward and add a small positive advantage on the environment tokens. One vector changes, and the same one-line config runs on the open SkyRL reference, on Tinker, and on managed post-training unchanged. We ran it live on a small Qwen model; the backend metrics came back namespaced skyrl.ai, the open reference stack running underneath.
The interesting part is what happens next
Once your workflow, tools, and rubric live in an OpenEnv environment, the same trace data that post-trains the model can improve the environment itself: curricula that generate harder tasks as the agent gets better, harness optimizers, new environments built from captured production traces. That is recursive self-improvement, and it is on the roadmap, not in a paper. The system writes its own next set of exercises, and each cycle sharpens the next. The learning stops living only in the weights and starts accruing in the gym, which is the part you own.
Start hill-climbing. The model should be swappable. The loop should be yours.
Take one real workflow, turn it into an OpenEnv-compatible environment with a clear outcome rubric, and start hill-climbing. The model should be swappable. The loop should be yours.
For the full walkthrough of the loop, the product details, and the non-parametric vs. parametric breakdown, see the companion post on the Microsoft Foundry blog.