“The price of reliability is the pursuit of the utmost simplicity.”
The agent demos all look beautiful. You ask the friendly chatbot a question, it thinks for a moment, it gives you an answer. Sometimes the answer is even right.
Then someone says the thing that ruins the demo:
“Can we get it to actually do things—and trust it to do them?”
The moment “do things” is in scope, the architecture problem changes. Now the agent needs to run code. It needs files. It needs network access. It needs a credential to call the next model. It needs to remember what it did yesterday. The friendly little chat suddenly has a workspace, a shell, a token, and a very real ability to break something expensive.
This post outlines the architecture I want around that agent before I let it loose: a LangGraph factory that talks to a Squad coordinator for judgment, then dispatches the dangerous parts to two different Azure Container Apps primitives: one for one-shot work, one for stateful work. The whole thing proved itself end to end last week, which is why I’m writing it down now.
And this isn’t a hypothetical I built to have something to write about. The triggering event was a real team that turned up wanting to use Squad in production—and, interestingly, they were a Node.js shop. They had TypeScript. They had LangGraph. They had a package-lock.json that had clearly earned the right to be respected. What they did not have was the Microsoft Agent Framework, which is inconvenient for my C# heart. They wanted Squad inside their existing application, and the answer couldn’t be, “Please rewrite your product in C# first.”
So the question stopped being whether Squad is nice and became a harder one: Where exactly does a judgment step go inside an app that already has a deterministic state machine, a tool surface, a CI pipeline, and a product manager who would prefer the demo not catch fire? That’s a different question from the last piece Brady Gaster and I wrote for Command Line, which was about what survives an agent session—make the agents disposable, keep the memory in Git. This post is about where the agents go and where their tools actually run.
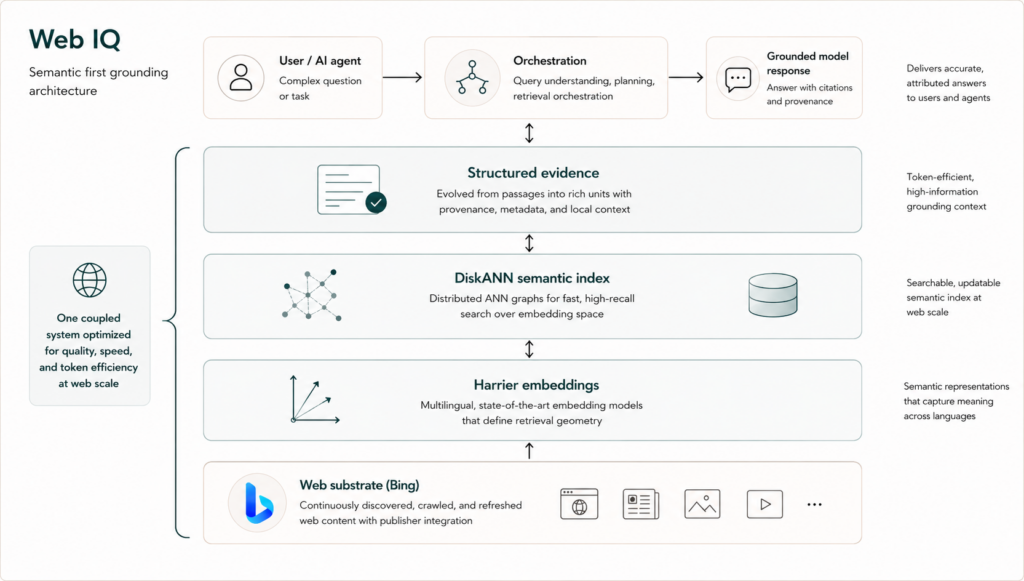
The shape I backed into has three layers: a brain that decides, two different pairs of hands that do the work, and a memory that carries the evidence from one step to the next. That is the first-order picture. The second-order detail—and it’s the one that actually matters—is that one of those two pairs of hands can hold a brain of its own.
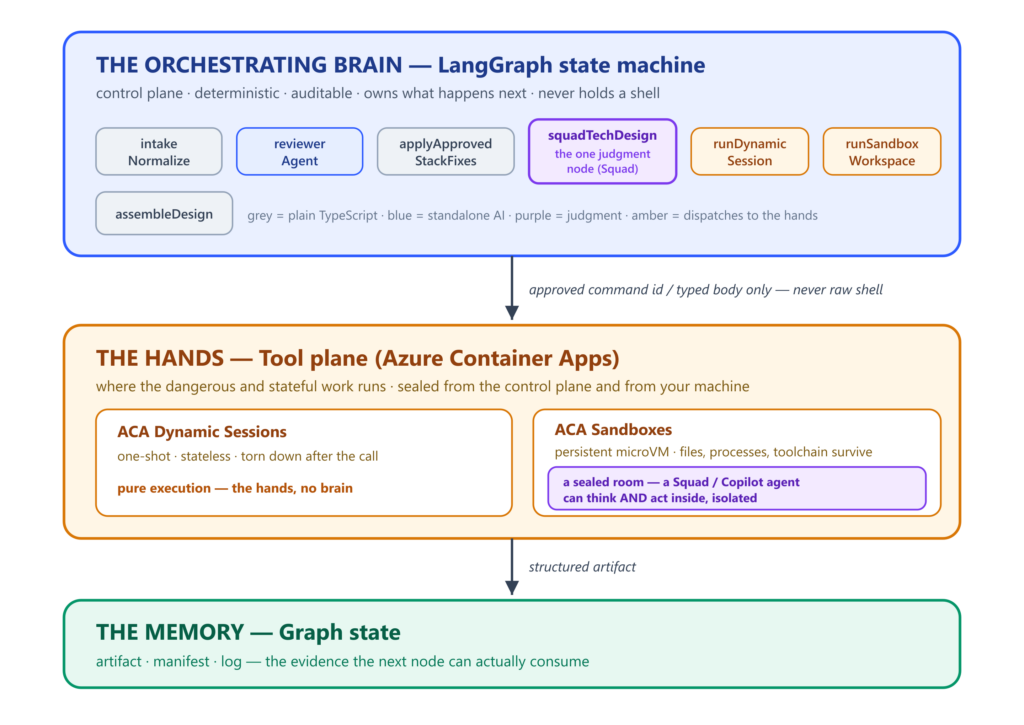
The three-layer shape: a LangGraph orchestrating brain that decides the flow, an ACA tool plane that runs the dangerous and stateful work, and graph state that carries the evidence between them. The orchestrating brain stays deterministic and never holds a shell; when a model needs to think with one, that thinking is sealed inside a sandbox.
The three problems agents create the moment they get hands
A chat agent has none of these problems, which is why chat agents are easy while agents that do things are hard.
Problem one is non-determinism. A model is great when you want it to weigh tradeoffs in a design document. It’s terrible when you want it to decide whether step three of a workflow should happen before or after step four. Workflows are product decisions. The order of operations doesn’t need a creative reinterpretation on every run.
Problem two is dangerous code. The moment the agent can run a shell, it can also run the wrong shell. It can wipe the wrong directory. It can pip-install a package it found on a sketchy index. It can pull a token from an environment variable and quietly post it somewhere that isn’t yours. None of this is malice. It is what happens when a probabilistic process gets a deterministic side effect.
Problem three is state across steps. A useful agent for non-trivial work needs a workspace. It checks out a repo, installs a toolchain, opens files, runs an analysis. The result of step one is the input to step three. If the workspace dies with the call, nothing accumulates. If it survives across calls, you have a different set of problems—but at least the right shape for the work.
Three problems. They don’t all want the same solution. The trick is to give each one its own.
The brain: A deterministic graph with one judgment node
LangGraph is the brain in this design because it is deterministic where I want determinism. It decides what runs, in what order, with what state, and what happens if a node fails. It does not invent steps. It does not improvise the workflow on each run. It is boring in exactly the right way.
Everything below runs on a sample I keep calling the factory, so it’s worth 30 seconds on what it models. The use case is an internal software factory: the shared platform team a large enterprise stands up so its business groups don’t each invent their own stack from scratch. A group shows up with an idea and a rough set of requirements. The factory reviews them against the organization’s approved technologies and best practices, rewrites the parts that don’t comply, folds in the operational signals the team supplied, and hands back a tech design the group can actually build from. It is small enough to read end to end and real enough to exercise every layer in this post.
The factory sample has seven nodes in a straight line: intake normalization, a standalone reviewer agent, deterministic stack fixes, the Squad design step, the Dynamic Sessions signal-analysis step, the ACA Sandbox workspace step, and a final assembler that produces one markdown design document.
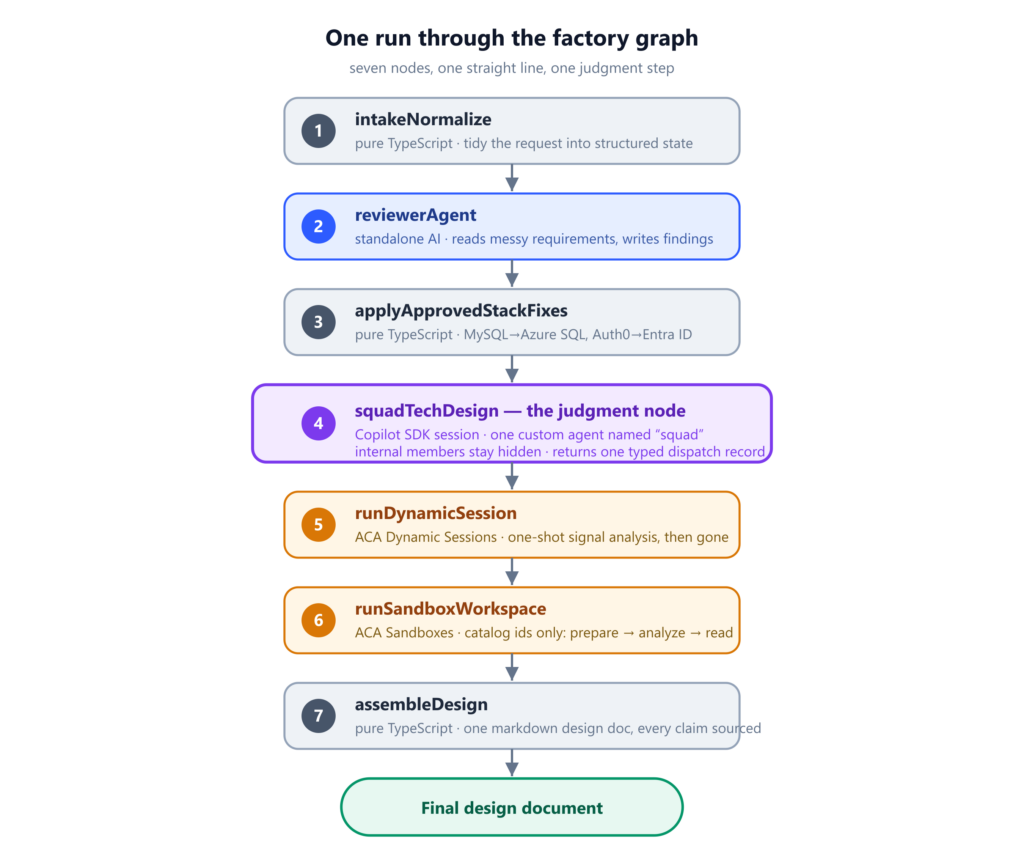
One run through the seven-node factory graph, from intake to the final design document. Six nodes are plain TypeScript or a single bounded AI call; the one in the middle—squadTechDesign—is where judgment is allowed to drive.
Six of those nodes are uncontroversial—plain TypeScript or a single bounded SDK call. The interesting one is the design step.
Wiring the seven nodes is the boring half. LangGraph’s StateGraph takes a typed annotation and a list of addNode / addEdge calls and gives you back a compiled, synchronous-looking graph the rest of the app can invoke. The graph below is the whole orchestration layer; there is no other dispatcher anywhere in the codebase.
// src/graph.ts (squad-langgraph-aca:wip)
return new StateGraph(FactoryStateAnnotation)
.addNode("intakeNormalize", intakeNormalize)
.addNode("reviewerAgent", reviewerAgent)
.addNode("applyApprovedStackFixes", applyApprovedStackFixes)
.addNode("squadTechDesign", squadTechDesign)
.addNode("runDynamicSession", runDynamicSessionNode)
.addNode("runSandboxWorkspace", runSandboxWorkspaceNode)
.addNode("assembleDesign", assembleDesign)
.addEdge(START, "intakeNormalize")
// ... linear edges in the same order ...
.addEdge("runSandboxWorkspace", "assembleDesign")
.addEdge("assembleDesign", END)
.compile();
The state every node reads and writes is one typed shape. Each node’s return value is a partial update—LangGraph merges it into the running state for the next node to read. No globals. No shared mutable singletons. The whole “memory between steps” story lives in one annotation declaration:
// src/graph.ts (squad-langgraph-aca:wip)
const FactoryStateAnnotation = Annotation.Root({
request: Annotation<FactoryRequest>(),
normalizedRequest: Annotation<NormalizedRequest | undefined>(),
dispatches: Annotation<DispatchRecord[]>(),
findings: Annotation<Finding[]>(),
designSections: Annotation<DesignSection[]>(),
signalArtifact: Annotation<DynamicSessionArtifact | undefined>(),
reviewArtifact: Annotation<SandboxReviewArtifact | undefined>(),
finalDesign: Annotation<string | undefined>()
});
That is the node where the brain hands the current graph state to a Copilot SDK session, registers a custom agent named squad, lets that agent use the repo-local team context as its working memory, and waits for a typed dispatch record. The internal Squad members never appear in the LangGraph state. The brain sees one public custom agent and one structured result. The complexity stays behind that one door.
The Copilot SDK call that opens that one door looks like this. The load-bearing lines are customAgents, agent: squadAgentName, and the structured sendAndWait return—the SDK gives you a way to register a named custom agent, pre-select it for the turn, and read back its assistant message as typed data. The brain never sees the agent’s internal reasoning, only its declared output:
// src/squad/copilotSdkCustomAgents.ts (squad-langgraph-factory)
const client = options.clientFactory?.(clientOptions) ?? new CopilotClient(clientOptions);
await client.start();
const customAgents = await createCustomAgents(repoRoot, input);
const tools = createFactoryTools(captured);
session = await client.createSession({
clientName: "squad-langgraph-factory",
model: options.model ?? "claude-sonnet-4.5",
workingDirectory: repoRoot,
tools,
availableTools: createAvailableTools(),
customAgents,
agent: squadAgentName, // HERE: "squad" is the only public-facing agent
onPermissionRequest: approveAll, // tools are deterministic, so blanket-approve is safe
// ...systemMessage, skipCustomInstructions, includeSubAgentStreamingEvents...
});
if (session.rpc?.agent?.select) {
await session.rpc.agent.select({ name: squadAgentName }); // belt + braces: pre-select
}
finalResponse = await session.sendAndWait(
{ prompt: createNodePrompt(input) },
options.timeoutMs ?? 120_000
);
return buildDispatchRecord(input, captured, finalResponse);
The custom agent itself is one entry—a name, a prompt loaded from .github/agents/squad.agent.md, and a hard-coded tool allowlist. Squad’s internal members and routing files (.squad/team.md, .squad/routing.md, .squad/agents/*) are passed in as internal context to that one agent; they are never registered as SDK agents the graph could select on its own:
// src/squad/copilotSdkCustomAgents.ts (squad-langgraph-factory) — createCustomAgents
return [{
name: squadAgentName, // "squad"
displayName: "Squad Coordinator",
description: "...returns public-safe typed technical design output.",
tools: squadCoordinatorToolAllowlist, // readApprovedStack, validateTechnology, recordFinding, draftSection
infer: true,
prompt: [coordinatorPrompt.trim(), "...", "Current graph-node context:", stateContext].join("\n")
}];
And the thing the brain ultimately reads back from that judgment node is a typed DispatchRecord—a contract Squad can fill but can’t widen. Findings and sections come back as plain data the next node can iterate over:
// src/types.ts (squad-langgraph-factory)
export type DispatchRecord = {
member: SquadMemberName; // "squad" for the LangGraph-facing seam
objective: string;
allowedTools: MemberToolName[];
findings: Finding[];
sections: DesignSection[];
};
That is the first architectural rule: Judgment is the only thing the brain delegates to a model. Everything else is code.
The reviewer step is a single-purpose SDK custom agent that reads messy requirements and writes findings into state. The deterministic substitution step (MySQL becomes Azure SQL, Auth0 becomes Microsoft Entra ID) is not an agent at all. It’s a switch statement. We don’t need a probabilistic process to pretend to be a switch statement.
// src/graph.ts (squad-langgraph-aca:wip) — applyApprovedStackFixes
const fixes: ApprovedStackFix[] = [];
const requestedTechnologies = source.requestedTechnologies.map((technology) => {
const replacement = replacementMap[technology.toLowerCase()];
if (!replacement) return technology;
fixes.push({ from: technology, to: replacement, reason: `${technology} is outside the approved sample stack.` });
return replacement;
});
This is the brain: a state machine with a known shape, one judgment node, and typed outputs the next nodes can read.
The first pair of hands: ACA Dynamic Sessions
The Squad node produces design sections. The next thing the design needs is a signal analysis on the operational signals the team supplied. That work is small, stateless, and isolated by definition.
ACA Dynamic Sessions is the right primitive for that lane.
Think of Dynamic Sessions as a pool of pre-warmed containers the platform spins up on demand. You call a run endpoint, attach an opaque high-entropy identifier, and the platform routes the call to a fresh container. When the call finishes, the container is torn down. There is no “yesterday” in this lane, and no shared file system across runs.
The whole client is a single POST with an Entra-issued bearer token and an opaque identifier the platform uses as the routing key. The identifier is generated per run and has no meaningful content—the pool uses it to map calls to containers; the app never reuses it:
// src/dynamicSessions/AzureDynamicSessionsClient.ts (squad-langgraph-aca:wip) — Run()
const token = await this.Credential.getToken(DynamicSessionsScope);
const url = this.BuildSessionUrl("/run"); // appends ?identifier=<opaque>
const response = await this.FetchFn(url, {
method: "POST",
headers: {
authorization: `Bearer ${token.token}`,
"content-type": "application/json",
},
body: JSON.stringify({
sessionId: request.SessionId,
task: { kind: "analyzeSignals", input: { /* tenantId, product, region, signals */ } },
}),
});
The sample wires Dynamic Sessions to its own custom container, not the generic Python sandbox. The container exposes two routes: a health check and a run endpoint. The body cap is 64 KB. The handler doesn’t call a shell. It doesn’t call a model. It runs one deterministic function that scores the input against a small keyword map and returns a typed artifact. The pool runs with egress disabled at the platform level—even if the worker decided to phone home, the call would not resolve.
// worker/src/server.ts (squad-aca-dynamic-sessions)
const maxRequestBytes = 64 * 1024;
const server = createServer(async (req, res) => {
if (req.method === "GET" && req.url === "/health") {
return sendJson(res, 200, { ok: true, service: "squad-aca-dynamic-sessions-worker" });
}
if (req.method === "POST" && req.url?.startsWith("/run")) {
const body = await readJson<SandboxRunRequest>(req); // 64 KB cap enforced in readJson
return sendJson(res, 200, executeDeterministicTask(body, "worker")); // no shell, no model
}
sendJson(res, 404, { ok: false, error: "Not found. Use GET /health or POST /run." });
});
The egress-disabled story is one flag on the pool itself. The whole “even if the worker decided to phone home” guarantee comes from that one line of provisioning—the worker container has no route to anywhere outside the pool:
# infra/create-session-pool.sh (squad-langgraph-aca:wip)
az containerapp sessionpool create \
--name "<SESSION_POOL_NAME>" \
--container-type CustomContainer \
--image "<ACR_LOGIN_SERVER>/squad-aca-dynamic-sessions-worker:<TAG>" \
--cpu 0.25 --memory 0.5Gi --target-port 8080 \
--network-status EgressDisabled \ # <-- the load-bearing line: no outbound network from the pool
--max-sessions 10 --ready-sessions 1
That’s more constrained than people expect when they hear “Dynamic Sessions.” The pool can run a model-driven shell if you want one. The sample explicitly does not, because the brain already does that work in the Squad node. The Dynamic Sessions lane is the place I want code, not judgment.
The local development mode runs the same function in-process—same code, different transport—so the local demo produces an identical artifact to the Azure demo. The pool is not a stub. It’s the same logic running far from your laptop.
Dynamic Sessions, in one line: stateless, one-shot, deterministic. Perfect for work that should never come back.
The second pair of hands—that can hold a brain: ACA Sandboxes
The other ACA primitive is doing a different job, and it took me a minute to internalize that it isn’t just “Dynamic Sessions, but bigger.”
ACA Sandboxes give you a persistent microVM. Real file system. Real process tree. Whatever toolchain the disk image includes—the GitHub CLI, npm, the Copilot CLI, whatever you bake in. You can suspend it. You can resume it. The state survives across calls, which is exactly what an agent that wants a workspace needs.
The sample treats that microVM as a workspace and exposes a TypeScript wrapper with only three verbs. Execute one named command. Capture a snapshot. Suspend. There is no run-shell. There is no write-file. There is no fetch-URL. The interface is deliberately too narrow to let the graph invent a new shell command at runtime.
// src/sandboxes/AzureSandboxWorkspace.ts (squad-langgraph-aca:wip)
export class AzureSandboxWorkspace implements SandboxWorkspace {
ExecCommand(commandId: string): Promise<SandboxExecResult>; // pick a catalog id; never build shell
CaptureSnapshot(): Promise<string | null>;
Suspend(): Promise<void>;
}
The body of ExecCommand is the boundary. It resolves the id through GetCommand, shells out via the aca CLI with the catalog’s pre-built shell string, and runs the captured stdout/stderr through a redactor before anything leaves the wrapper. The graph never sees raw subprocess output:
// src/sandboxes/AzureSandboxWorkspace.ts (squad-langgraph-aca:wip)
async ExecCommand(commandId: string): Promise<SandboxExecResult> {
const command = GetCommand(commandId); // throws on unknown id (allowlist)
const argv = [
"sandbox", "exec",
"--group", this.SandboxGroup, "--id", this.SandboxId,
"--command", command.Shell, // pre-built shell from the catalog
];
const result = await this.RunAca(argv);
return {
CommandId: commandId,
Stdout: RedactText(result.Stdout), // redact Bearer / gh_* / JWT-like before egress
Stderr: RedactText(result.Stderr),
ExitCode: result.ExitCode,
};
}
The “named command” part is where the safety story lives. The sandbox lane ships with a command catalog of five entries: prepare workspace, analyze workspace, read artifact, inspect toolchain, and one I will come back to in a minute called the Copilot prompt proof. Each entry has a stable id and a fixed shell string. The graph picks an id; the wrapper resolves it and shells out. If the id isn’t in the catalog, the lookup throws with the allowlist in the error message. No fuzzy match. No fallback shell. No “execute anyway.”
// src/sandboxes/commandCatalog.ts (squad-langgraph-aca:wip)
export const Commands: Record<string, SandboxCommand> = {
prepare_workspace: { CommandId: "prepare_workspace", Description: "Create deterministic workspace input files.", Shell: BuildPrepareWorkspaceShell() },
analyze_workspace: { CommandId: "analyze_workspace", Description: "Run a deterministic analysis; write review artifact.", Shell: BuildAnalyzeWorkspaceShell() },
read_artifact: { CommandId: "read_artifact", Description: "Read the generated review artifact.", Shell: BuildReadArtifactShell() },
inspect_toolchain: { CommandId: "inspect_toolchain", Description: "Inspect copilot/gh/node/npm/squad versions.", Shell: BuildInspectToolchainShell() },
copilot_prompt_proof: { CommandId: "copilot_prompt_proof", Description: "Phase 3 acceptance: real Copilot prompt inside the sandbox using the sandbox-group credential.", Shell: BuildCopilotPromptProofShell() },
};
export function GetCommand(commandId: string): SandboxCommand {
const command = Commands[commandId];
if (!command) {
const allowed = Object.keys(Commands).sort().join(", ");
throw new Error(`Unsupported sandbox command '${commandId}'. Allowed: ${allowed}`);
}
return command;
}
That is the most important rule of the sandbox lane: The orchestrating brain picks command ids; it never builds shell. Every shell string that runs inside the sandbox was authored by a human, lives in source control, and can be diffed in a pull request. The probabilistic process selects from a menu. The menu doesn’t change at runtime.
Adding a capability means adding a new entry, not teaching an existing one a new trick. In return, you get an audit log that is actually useful—which ids ran, in what order, with what exit codes. The driver stops on the first non-zero exit, runs the suspend in a try/finally so a thrown exception still releases the billable compute, and pushes captured stdout through a redactor before it ever leaves the wrapper. Nothing leaks across the boundary through process state or scratch files.
// src/sandboxes/runSandboxWorkspaceNode.ts (squad-langgraph-aca:wip)
const results: SandboxExecResult[] = [];
let reviewBody = "";
try {
for (const commandId of plan) { // plan from DefaultCommandPlan()
const result = await workspace.ExecCommand(commandId);
results.push(result);
if (commandId === "read_artifact" && result.ExitCode === 0) reviewBody = result.Stdout;
if (result.ExitCode !== 0 && commandId !== "inspect_toolchain") break; // stop-on-nonzero
}
} finally {
if (options.SuspendAtEnd ?? mode === "azure") await workspace.Suspend(); // always release compute
}
And here is where the brain-and-hands metaphor would mislead you if you took it too literally. A sandbox is not a mindless pair of hands. One of those catalog commands can start a real Copilot session inside the microVM—a Squad agent that reads, reasons, and decides, holding a shell and a credential and a workspace, the exact things I spent the first half of this post keeping away from the orchestrator. That is not a contradiction. It is the whole point. The orchestrating brain stays deterministic and shell-free; and when you genuinely need a model to think with dangerous capabilities, you don’t hand them to the control plane—you seal that thinking inside a sandbox, where a second brain can think and act in a room locked from the outside. The hands can hold a brain. It just has to be a contained one.
Two pairs of hands, different shapes, different jobs
Both of these are containers. Both are managed by ACA. Both have egress controls. They are not interchangeable.
| Dynamic Sessions | ACA Sandboxes | |
| Lifecycle | One-shot. Torn down after the call. | Persistent microVM. Suspend, resume. |
| State across calls | None. Each call is fresh. | File system, processes, toolchain survive. |
| What the orchestrator sends | A typed JSON body. | A catalog command id. |
| What runs inside | One deterministic function. | A pre-built shell from the catalog—sometimes a whole agent. |
| Can a brain think inside? | No. Pure execution. | Yes—a sealed, contained one. |
| Right job | Stateless deterministic work. | Long-lived workspace. Installed CLIs. Agent prompts that need credentials. |
Picking the right one for each lane is most of the architecture. The factory sample uses both because the workflow has both kinds of work in it. The signal analysis is one-shot. The workspace review is multi-step. Forcing them into the same primitive would either drag stateless work into a persistent sandbox (and pay for compute you don’t need) or drag stateful work into a one-shot container (and lose the artifacts the next call needs to see).
Use the right pair of hands for the job.
What a single run actually looks like
A user gives the factory a request. The team is Contoso Field Apps. The goal is a regional intake app with an approval workflow. The proposed stack is Power Apps, MySQL, Auth0, Power Automate. There are constraints—must use approved identity, must produce an auditable design—and operational signals that read like things an actual ops team would say. “Save button timeouts spike on Friday afternoons” is in there, because somebody’s Friday afternoons are always like that.
The graph runs.
Intake normalization tidies up whitespace. The reviewer agent reads the request and writes findings into state—it notices “audit” was requested but no retention period was specified. A deterministic step rewrites the stack list: MySQL becomes Azure SQL, Auth0 becomes Microsoft Entra ID. The fixes get appended to state so the design can show its work later.
Now the brain hits the judgment node. The Squad design step opens a Copilot SDK session, registers the squad custom agent with its bounded tool allowlist, pre-selects it for the turn, and sends the current state as context. Squad reads its team context, decides which sections to draft, calls the deterministic tools, and returns a typed dispatch record.
Now the tool plane. The Dynamic Sessions node signs an Entra token, calls the worker pool, and the worker scores the signals against the keyword map. The pool returns a typed signal artifact—risk score, findings by category, recommended next step.
The Sandbox node does the longer story. It resolves the sandbox group and id, then walks the catalog: prepare the workspace, analyze it, read the artifact back. Each step shells out with a pre-built shell. The captured stdout is redacted on the way out. The driver suspends the sandbox in a finally.
Finally the assembler runs. It reads everything from state and produces a five-section markdown document with the stack substitutions, the Squad-drafted sections, and both ACA artifacts as evidence the work was actually done. Every claim has a node that produced it and a typed value behind it.
That’s a normal run. The boring kind. The only kind I want from anything that talks to production.
The punchline: Where the credential actually lives
The hardest problem in agent execution isn’t, “Where do we run shell?” The container model solves that. The hardest problem is, “How does the agent inside the sandbox prove it has an identity to call out to a model with, without that identity ending up somewhere your application can read it?”
There are three approaches that look reasonable and are wrong.
You can bake the token into the disk image. Build the image with a Copilot credential directory already populated, push it to your registry, point the sandbox at it. It works. Until the token rotates. Until someone pulls the image from the registry cache and grabs the layer with the credential in it. The token’s blast radius is now whoever has read access to the registry, which is almost always a much bigger set than whoever should hold the credential.
You can copy the Copilot credential from the host at provisioning. Cleaner. The image stays neutral. But now the token sits on the sandbox’s disk, indistinguishable from any other workspace file. It’s in snapshots. It’s in memory dumps. A misconfigured catalog command that lists files puts the path in stdout, which the redactor catches sometimes and misses other times. The credential lives in user-visible state, and user-visible state has a hundred ways to leak.
You can pass it via an environment variable. Lowest effort. Highest risk. Environment variables are inherited by every child process. They show up in process introspection. They survive in coredumps. The moment a tool dumps the environment for debugging, the credential lands in the artifact that goes back to graph state.
All three share the same flaw: The credential is in the application’s data plane. Whatever read access the application has, the credential effectively has. That is the model ACA Sandboxes is designed to break.
The right answer is to lift the credential one layer up—onto the sandbox group itself, which is its own Azure resource with its own role assignments and its own audit trail.
The provisioning recipe is three commands. Create the sandbox group. Attach a GitHub Copilot credential to it—the platform takes the secret material and gives you back an opaque credential id. Create a sandbox in the group, bind it to that credential id, and set egress to default-deny with three explicit allowances: github.com, api.github.com, and the Copilot API wildcard. The token never lands in the disk image. It never lands on the host filesystem. It never lands in an environment variable. The platform injects it at provisioning time through a path the application cannot enumerate. Rotation is a control-plane operation against the group; existing sandboxes pick up the new credential without redeployment.
# infra/create-sandbox-group.sh (squad-langgraph-aca:wip)
# 1. Create the sandbox group.
aca sandboxgroup create --name "${GROUP}" --resource-group "${RG}" --region "${REGION}"
# 2. Attach a credential. It lives on the group, not the disk image — so it is rotatable.
aca sandboxgroup credential create --group "${GROUP}" --resource-group "${RG}" --type github-copilot
# 3. Create a sandbox bound to the credential, default-deny egress, allowlist only what the model needs.
aca sandbox create \
--group "${GROUP}" --resource-group "${RG}" --disk copilot \
--credential "${GITHUB_COPILOT_CREDENTIAL_ID}" \
--egress-default Deny \
--egress-rule "github.com:Allow" \
--egress-rule "api.github.com:Allow" \
--egress-rule "*.githubcopilot.com:Allow"
The default-deny egress is the other half. Without it, a leaked credential could still phone home anywhere. With it, the sandbox can only reach the three hosts the agent needs to talk to a Copilot model. The token is real, the prompt works, and there is nowhere else for it to go.
The proof that this composes is a small catalog command—the Copilot prompt proof I mentioned earlier. Print the CLI version. Run a single non-interactive prompt asking the model, “What is 2+2?” with instructions to reply with one integer and no prose. Capture the answer. Exit. The deterministic prompt is the smallest possible signal that the credential resolved, the egress allowed the call, and the model returned.
// src/sandboxes/commandCatalog.ts (squad-langgraph-aca:wip) — BuildCopilotPromptProofShell
return (
"set -eu\n" +
"echo '== copilot CLI version =='\n" +
"copilot --version\n" +
"echo '== authenticated prompt (deterministic answer expected) =='\n" +
"timeout 90 copilot -p \"What is 2+2? Reply with a single integer and no prose.\" 2>&1 | tr -d '\\r' | tail -10\n" +
"echo '== proof complete =='\n"
);
That command ran end to end against a real Azure subscription last week. The prompt resolved through the sandbox-group credential. Default-deny egress was active. The model returned a deterministic answer in eight seconds and 8.33 AI credits. The token was not in the disk image, not copied from the host, and not in any environment variable.
That is the punchline. The architecture is publishable now because the credential is out of reach of the data plane. Without that, you can have all the catalogs and all the egress rules and all the suspend lifecycles you want, and you’re still one log paste away from a leaked token.
Put the credential where the application can’t find it. Let the platform inject it. Default-deny the network. Run a tiny prompt to prove it works. Then sleep.
What’s shipped, what’s coming
A short status note, because I would rather you go look at the code than take my word for it.
Three of the four repos are public. The LangGraph + Squad baseline is squad-langgraph-factory. The Dynamic Sessions sibling is squad-aca-dynamic-sessions—the custom-container worker, the pool provisioning script, the TypeScript client. The ACA Sandboxes sibling is squad-aca-sandboxes-workspace, written in Python, with a sister catalog and a documented safety-gate model.
The unifier—the one repo where both ACA primitives wire into the same LangGraph graph and the seven-node flow runs end to end—is still private. It lives at squad-langgraph-aca; the integration is on a work-in-progress branch. Main is the imported baseline; wip is the real thing. The repo flips to public once the last roadmap phase lands—the boring one with the full README, the architecture diagrams, the run screenshots. The interesting work is done.
The pattern is portable. The brain doesn’t have to be LangGraph. The judgment node doesn’t have to be Squad. The lanes don’t have to be these two ACA primitives. What you need are four shapes: a deterministic state machine, a narrow judgment seam, two execution lanes for two kinds of work, and a credential model outside your application’s data plane.
Get those four right, and your agent can have hands without becoming the reason you carry a pager.