

Humans and AI don’t search the same way. As people increasingly turn to chatbots and agents for information, grounding that AI—connecting it to fresh, relevant, and authoritative information—takes on new importance as foundational infrastructure. Microsoft’s grounding layer already powers most of the world’s major AI assistants. And today at Build, we took that work further with Web IQ, a new grounding system for the agentic web.
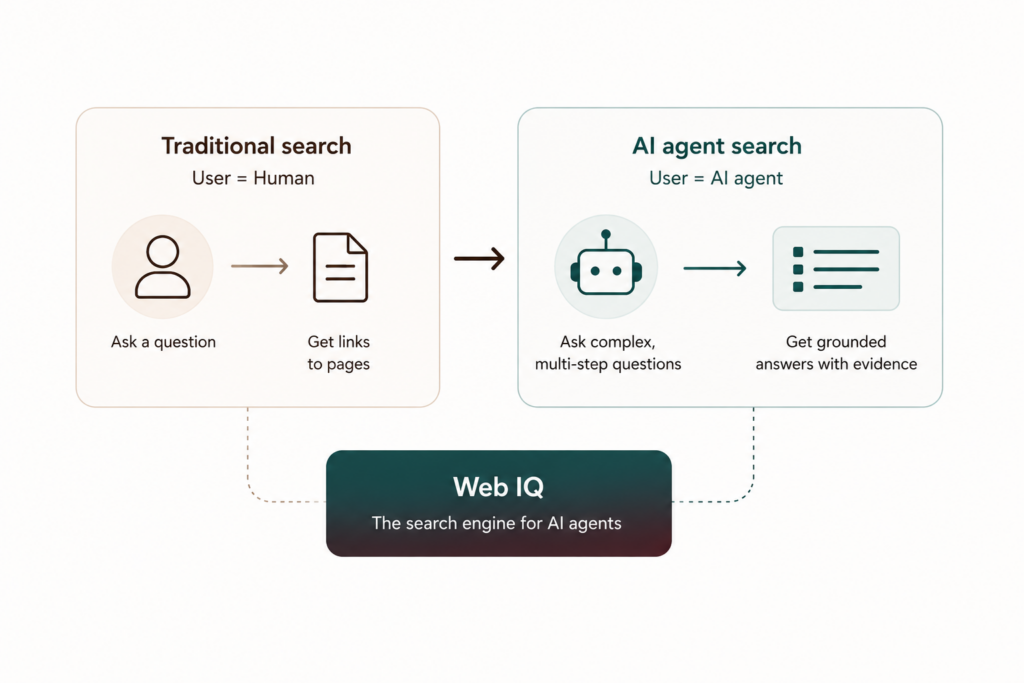
Web IQ delivers industry-leading quality, sub-165ms P95 latency (~2.5× faster than the nearest alternative), token-efficient retrieval, respecting publishers’ preferences. The same infrastructure powering Copilot, ChatGPT, enterprise systems from Nasdaq, and others, is now available as a neutral, MCP-native, model-agnostic platform. In this post, we’ll explore the architectural challenge, the Web IQ stack, and how we optimized for speed at scale.
Grounding redefines the optimization problem
Most discussions of AI systems still start with models. But once those systems are deployed at scale—especially in search, copilots, and agentic workflows—the dominant bottleneck shifts. The central problem becomes grounding: what information reaches the model, how fresh it is, how much context can be included, and how quickly that evidence can be delivered.
In a grounding system, those requirements collapse into three tightly coupled constraints: latency, quality, and token efficiency.
In classical search, these dimensions can often be traded-off relatively independently: A slower system can still be useful if it returns strong document results, and an imperfect ranking can still succeed if the user can inspect and repair the outcome. Inside an AI inference loop, that decoupling disappears.
In AI search and agentic systems, grounding sits inside the inference loop. Retrieval directly shapes generation, tokens determine both cost and latency, and missing or stale context propagates into reasoning errors rather than degrading gracefully. The optimization target is therefore no longer a ranking function in isolation, but rather a coupled system operating under latency, quality, and token-efficiency constraints. In that setting, grounding goes from a component to a system architecture problem.
Semantic‑first as a system design principle
Before describing Web IQ’s architecture, it helps to name the underlying shift more precisely: Large‑scale retrieval is moving from hybrid stacks, where lexical systems dominate first‑stage recall and dense models re-rank, toward semantic‑first systems in which representation learning defines the primary retrieval space.
That shift is now practical because modern embedding models preserve substantially more of the relevance signal at retrieval time, and ANN infrastructure is mature enough to search that space under production latency constraints. Just as importantly, retrieval is no longer limited to one vector per document. Instead, the effective unit can be a passage, span, or a small set of learned representations that retain finer interaction structure until late in the pipeline.
- Content is indexed as semantic representations rather than only lexical postings
- Candidate generation operates over neighborhoods in the embedding space, often at passage or sub-document granularity
- Fine relevance signals can be deferred to later interaction stages instead of being collapsed entirely into a single early score
- Lexical matching remains useful as a constraint, calibration signal, and fallback for exactness-sensitive cases
Rather than eliminate hybridization, this relocates it. In a semantic‑first stack, dense retrieval becomes the default access path, while later stages recover precision through richer interaction, filtering, calibration, and task-specific refinement. That choice propagates through the system: how content is chunked, how representations are trained, what the ANN index must preserve, and how evidence is assembled for downstream reasoning.
This direction has been visible inside Bing for years: shift more of the retrieval quality into learned representations, reduce dependence on head-query interaction logs, and expose content that lexical access paths and click priors systematically underserve. The long-term implication is a retrieval stack whose first stage is semantic by construction and whose later stages recover fine-grained matching only where it matters.
Web IQ is the first grounding system built end-to-end around that retrieval premise.
A reference architecture for grounding: The Web IQ stack
At the base of Web IQ is a retrieval system operating at global scale, but the key design choice is that documents are no longer the primary unit of access. The system is organized around both semantic representations of content and the operational question that follows from that choice: how to search a global embedding space with high recall, bounded latency, and enough structure preserved for downstream grounding.
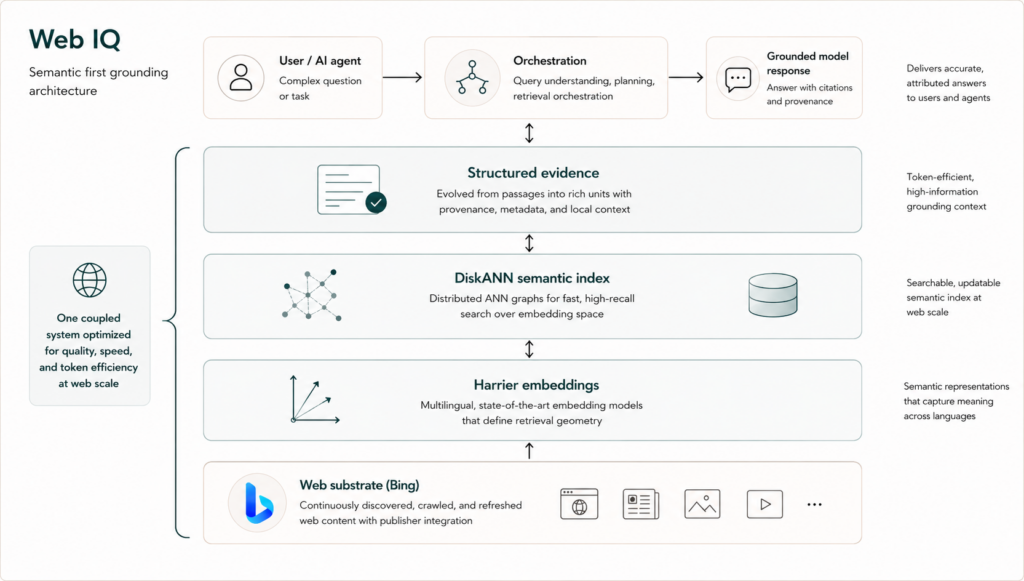
That immediately elevates two components from implementation details to system primitives: the embedding model, which determines what notions of relevance are geometrically recoverable, and the ANN index, which determines whether that geometry can be searched fast enough and updated often enough to reflect the live state of the corpus.
Harrier: Embedding as the geometry of the system
In a semantic‑first system, the embedding model defines the retrieval geometry. It determines which documents, passages, or sub-document units are near a query, which distinctions are preserved under compression into vectors, and which relevance signals must be recovered later through more expensive interaction.
Formally, Harrier, our family of custom-trained and open-source multilingual text embedding models, learns a mapping:
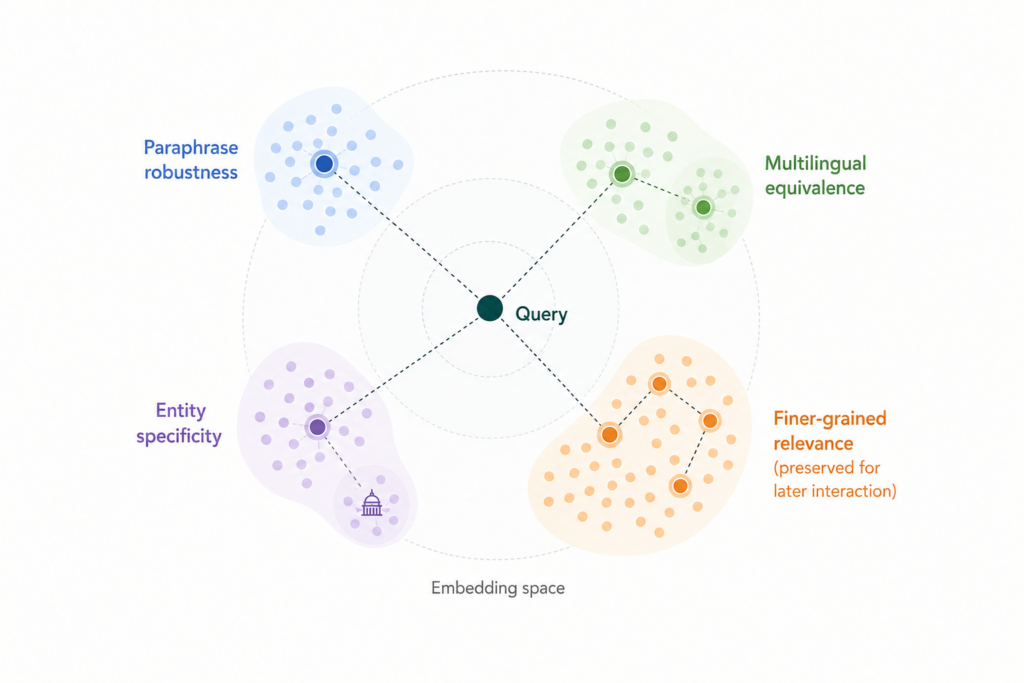
The formulation is simple, but the systems implication is severe: Retrieval can only surface structure that the embedding space preserves. If multilingual equivalence, paraphrase robustness, entity specificity, or fine topical distinctions aren’t encoded well enough in the representation, the downstream stack can at best compensate partially and at additional cost.
Harrier is trained using large-scale contrastive learning, combining billions of weakly supervised pairs with high-quality curated examples and synthetic data generation.
The goal is not merely high benchmark retrieval accuracy. The model must produce a space that remains stable across languages, robust to phrasing variation, efficient under ANN search, and aligned with the kinds of evidence selection and reasoning tasks the grounding layer performs later in the pipeline.
A key design choice in Harrier is the use of decoder‑only architectures with last‑token pooling and normalization, producing dense representations that are operationally consistent across tasks. That differs from the older encoder-centric embedding pattern and reflects a tighter coupling between retrieval models and the broader LLM stack.
In practice, Harrier builds on modern decoder backbones and is refined through staged training: broad pretraining to inherit linguistic and world knowledge, contrastive specialization to shape retrieval behavior on domain data, and distillation into smaller deployment variants. Distillation matters not only for cost; it’s what allows the system to preserve a compatible embedding geometry across deployment tiers while pushing latency and throughput in the right direction.
The result is an embedding model that is competitive on public benchmarks and, more importantly, behaves predictably under production workloads where distribution shift, multilingual traffic, and latency constraints matter more than leaderboard position.
DiskANN: When geometry meets reality
If Harrier defines the geometry, DiskANN3 defines what is operationally achievable inside it.
Approximate nearest neighbor search is often presented as an algorithmic trick—at web scale, it’s an operating constraint that determines the memory footprint, recall-latency frontier, and freshness envelope of the entire retrieval system.
DiskANN3 matters because it provides high-recall streaming search and operational flexibility on memory vs. throughput.
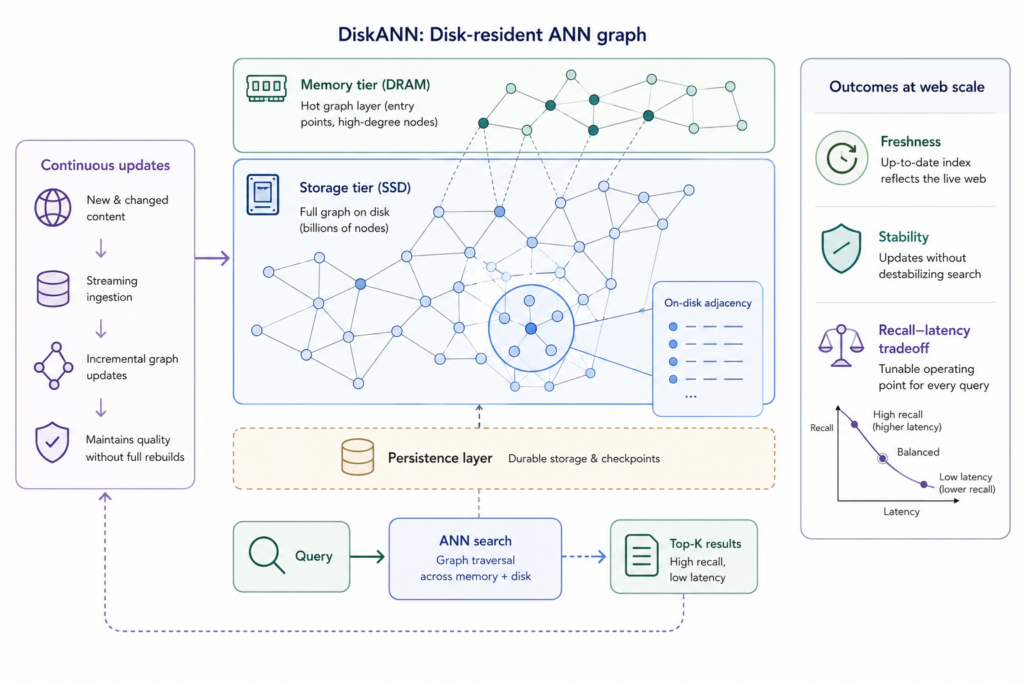
It decouples update and query logic which controls index quality from storage details. This allows high-recall search from different memory regimes, from disk-resident regimes avoiding the requirement that the full graph and vectors live in memory to purely memory-based indices for highest throughput and the spectrum in between.
But the more consequential issue isn’t static search quality; it’s whether the index can absorb continuous updates without losing stability.
In a grounding system, retrieval is only as current as the index, and stale graph structure shows up immediately as missed evidence, longer prompts, and more retries downstream.
In Web IQ that means distributed ANN graphs, streaming update paths, and mutation strategies that avoid frequent full rebuilds. Rather than simply fast query-time traversal, the objective is a semantic index that can remain both searchable and live.
New updated logic in DiskANN3 makes the update problem explicit: Proximity graphs are hard to mutate because local connectivity is fragile, and naive deletions or insertions can degrade search quality or force rebuilds. Solving that moves the system toward a truly streaming semantic index that takes only few milliseconds to make new content searchable, and always retains high search quality without full index rebuilds. This is essential for providing accurate grounding to AI agents.
Evidence objects: Controlling token economics
Once retrieval produces candidates, the next problem is context construction: selecting and packaging the evidence that the model will actually consume.
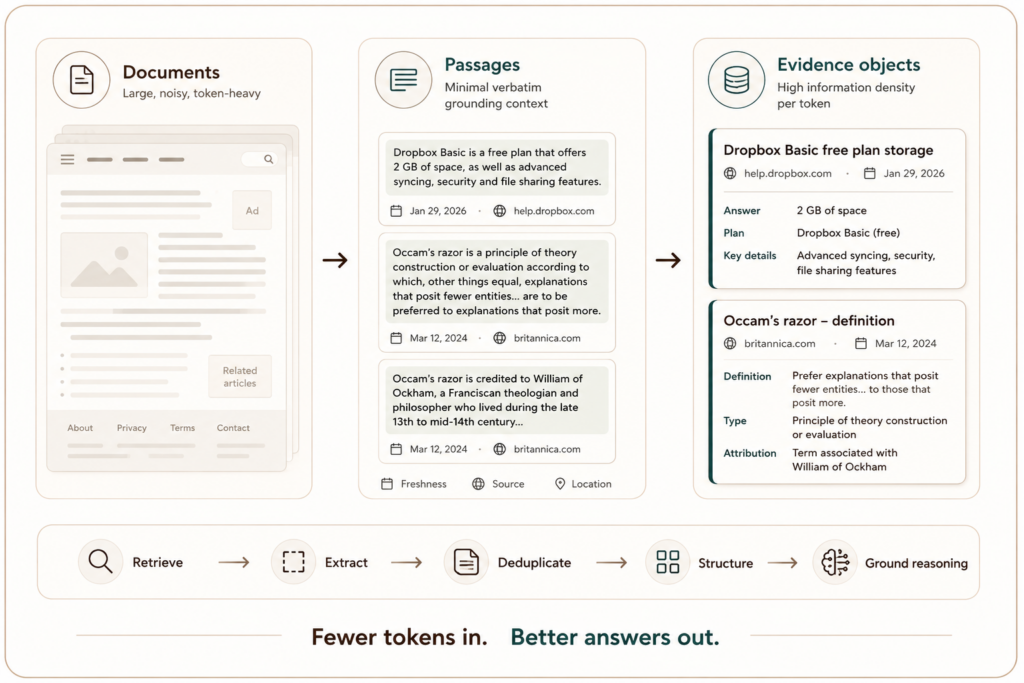
Web IQ departs from the document-centric search stack. Beyond just handing whole documents to the model, it can construct evidence objects: passage-level units with provenance, structural metadata, and enough local context to remain interpretable when detached from the source page. The aim is to preserve the evidence needed for reasoning without paying the token cost of full-document recall.
That changes the optimization target from document relevance to information density per token. Better evidence objects reduce prompt size, improve reasoning quality by concentrating the relevant facts, and preserve attribution so that outputs remain inspectable. This is the practical meaning of returning the most relevant chunks rather than entire documents.
Orchestration: The hidden system layer
At the top of the stack sits orchestration, which has become one of the most important components precisely because AI queries aren’t limited to short keyword expressions. Instead, they’re often long, compositional, and dependent on prior conversational state.
The orchestration layer interprets those requests, maps them onto retrieval strategies, executes those strategies across distributed infrastructure, and assembles evidence under strict latency and context-window constraints. Because it operates statefully against short-term memory and partial prior results, this layer is better thought of as execution planning for grounding rather than as a thin wrapper around search.
Optimizing for speed at scale
A grounding system also must be fast enough to remain inside an interactive inference loop. In practice, that means designing towards 100ms search latency—not as a marketing target, but as a systems target. Once retrieval, evidence construction, and orchestration sit on the critical path of generation, every additional millisecond increases both user-visible delay and the probability of cascading retries.
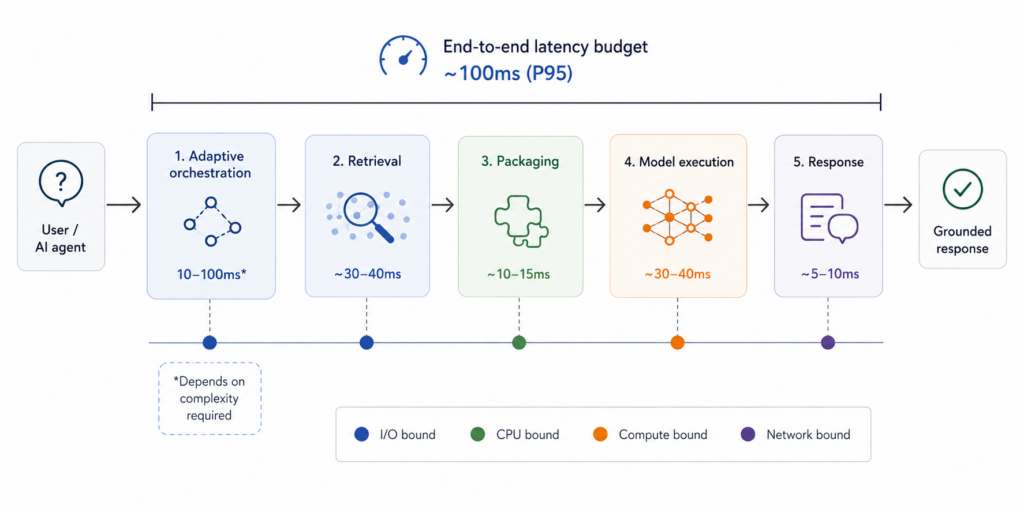
At that scale, performance is governed less by median latency than by the tail. The system therefore must be engineered around microsecond-level budget discipline across network hops, storage access, ANN traversal, and model execution, with aggressive control of tail amplification, careful failure handling, and degradation paths that preserve correctness when subsystems are slow or unavailable. Speed isn’t one optimization; it’s a property of the entire distributed pipeline.
That in turn makes efficiency a first-order design principle. Embedding models and re-ranking stages have to run on extremely efficient kernels and inference engines; data movement has to be minimized; and batching, caching, and memory layout have to be tuned for real workloads rather than benchmarks. The result is a culture of relentless performance work: shaving tail latency, reducing waste in every stage, and treating throughput, reliability, and latency as coupled properties of the same system.
The web as substrate: Bing, crawling, and the system beneath grounding
All of the layers above assume something more fundamental: a high-fidelity, continuously updated representation of the web. Far from a static dataset, that substrate is a dynamic, adversarial, multi-stakeholder system whose content, structure, and incentives change continuously.
For agentic grounding, crawl quality is upstream of answer quality. If the system doesn’t discover the right pages, revisit them at the right cadence, or parse them into stable representations, retrieval can’t recover the missing evidence later. At web scale, that makes crawling and indexing first-class systems problems: deciding what to fetch, when to revisit it, how to normalize heterogeneous content, and how to propagate updates through a distributed index without taking the system offline or destabilizing retrieval semantics.
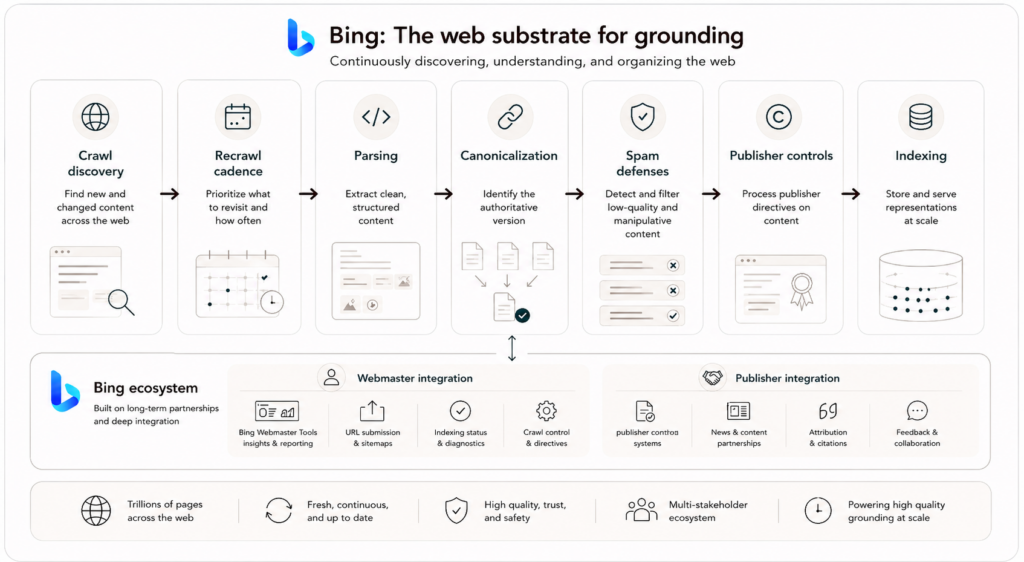
The web is also an ecosystem, not just a corpus. A production crawler must operate with politeness, respect publisher constraints, and preserve attribution, usage and quality signals from crawl through index construction and into evidence objects. Those constraints are part of the grounding system itself because the model can only cite and reason over evidence that has been collected, interpreted, and packaged responsibly.
Another complication is that the web responds to retrieval systems: Content is optimized for ranking, deduplicated, and continuously reshaped. Covering trillions of pages therefore takes more than bandwidth. It requires sophisticated models for discovery, canonicalization, spam detection, language understanding, and change prediction, together with trust and quality defenses that keep a semantic-first stack stable under continuous drift.
That’s why a long-lived system like Bing matters to Web IQ. Broad coverage isn’t only a matter of crawl volume; it depends on years of accumulated infrastructure, change models, publisher integration, anti-spam signals, and operational feedback. For agentic grounding, that history matters because a system can only ground against the web it has learned to discover, understand, and maintain over time.
A system perspective on grounding
The point here isn’t that any individual component is unprecedented. Embedding models, ANN indexes, crawlers, and orchestration layers all existed before. What changes in Web IQ is that they’re treated as one coupled system, organized around semantic-first retrieval, and optimized for the constraints that agentic grounding imposes.
Taken together, the system perspective is straightforward:
- Embeddings define what is geometrically retrievable
- ANN infrastructure determines whether that representation can be served with sufficient recall, freshness, and latency
- Evidence objects determine how efficiently the model can consume grounded context
- Orchestration, performance engineering, and crawl quality determine whether the pipeline can operate reliably at web scale
At that point, grounding is no longer an extension of search. It is a core infrastructure layer for agentic AI.