
AI is entering a new phase, and agents are the mechanism that will turn it into real economic impact.
We’re moving beyond models that generate text or code, and into systems that act by retrieving data, calling tools, executing workflows, and making decisions across environments. Frameworks like LangChain, AutoGen, CrewAI, and the Microsoft Agent stack have made it straightforward to build agents that can reason and operate end-to-end. When software starts acting on behalf of people, the surface area of automation expands across every workflow, every system, and every industry.
That shift introduces a new problem: As agents gain autonomy, the question is no longer just what they can do, but what they should be allowed to do and who defines those boundaries. Recent industry work highlights failure modes that don’t exist in traditional systems: tool misuse and unintended actions across multi-step failures that emerge across agent workflows. At the same time, regulatory expectations are accelerating, with new requirements around high-risk AI systems and accountability already coming into play.
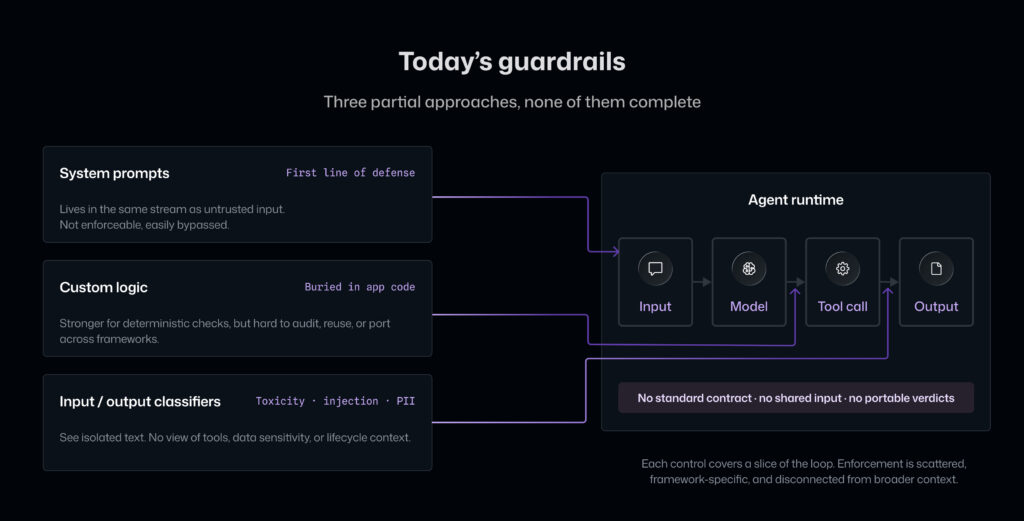
Today, governance largely lives in the development layer. Individual teams embed rules in prompts, application code, or framework-specific hooks. These controls are fragmented, inconsistent, and tightly coupled to how each agent is built. There is no standard mechanism by which a security or compliance team can define, enforce, and audit policy across agents.
Why the existing playbook breaks
Traditional security models assume a fixed actor and a fixed scope. With agents, the same credential that may be safe in one moment becomes risky in the next. A Slack token that’s fine for posting a meeting summary becomes dangerous the moment the agent has read a document marked confidential or included external users in the group. Traditional access control has no vocabulary for this: It can only answer “is this credential allowed to call this resource?”—not “given everything this agent has touched in this conversation, is this call still safe?”
Customers told us they were patching these gaps by stitching together classifiers, validations, and custom checks throughout their codebases. Every team had built some versions of this. We consistently saw the same patterns emerge.
- System prompts are often the first line of defense. They tell the agent what it should or should not do. They’re useful, but they aren’t enforceable. A prompt instruction lives in the same stream as user input, retrieved content, tool results, and potentially attacker-controlled text.
- Custom logic inside the agent can provide stronger guarantees for deterministic checks. But those rules are usually buried in application code. They’re hard to audit, hard to reuse, and hard to move when the team changes frameworks.
- Input and output classifiers help detect risks like jailbreaks, prompt injection, toxicity, or sensitive content. But classifiers often only see isolated text. They don’t automatically know which tool is about to run, what data labels are attached, or what context the agent has accumulated.
- Framework-specific guardrails (OpenAI Agents SDK input/output guardrails, Semantic Kernel filters, LangChain callback handlers, Anthropic tool-use callbacks) get the shape right but stop short. They’re the native extension points each framework exposes, which means the same policy has to be rewritten for every framework an organization uses, and a security team has no single place to author or audit controls.
- General-purpose policy engines (OPA/Rego, Cedar) answer authorization questions deterministically on structured inputs. They’re mature, expressive, and widely understood. But they have no model of an agent loop, no notion of when in a lifecycle to consult them, what state to collect, or how to enforce the verdict in the host runtime.
Across all these approaches, the gap is the same: Enforcement is scattered, framework-specific, and disconnected from the broader context of the agent’s lifecycle. The result, in practice, is that agent security ends up scattered across system prompts, framework callbacks, application code, content classifiers, and policy engines, with no single contract that describes how policies should be evaluated and enforced.
Introducing Agent Control Specification (ACS)
ACS is an open specification and reference implementation for the runtime governance layer of AI agents. It’s a new module within Microsoft’s Agent Governance Toolkit (AGT), extending how developers manage and govern AI agents. Its core artifact is a portable manifest that defines where, when, and how policies are evaluated and enforced across the full agent lifecycle, independent of the agent framework, the runtime, or the policy engine that authors the rules themselves.
ACS provides the missing layer that makes policy languages like Rego usable in the agent context: the standardized hooks, inputs, and enforcement contract. It owns the orchestration around policy evaluation:
- Lifecycle interception: where checks happen in the agent loop
- Canonical input shaping: what structured context is passed to the policy engine
- Evidence collection: how classifiers, DLP services, judges, or endpoints contribute facts
- Information flow checks: how labels and tool clearances are enforced
- Verdict normalization: how policy results become standard ACS decisions
- Final enforcement: how allow, warn, deny, or escalate verdicts, plus redaction effects, are applied by the host
- Fail-closed handling: what happens when policy, evidence, or verdict processing fails
ACS: Open standard interception policies
ACS defines eight interception points where policies can be evaluated against the agent’s runtime context. Each point evaluates a policy against the current snapshot, and the policy can allow, warn, deny, or escalate the action.
agent_startup: evaluate configuration and environment before the agent begins runningInput: inspect user input before the model sees itpre_model_call: inspect the full context being sent to the modelpost_model_call: inspect the model’s response before the runtime acts on itpre_tool_call: inspect tool name and parameters before executionpost_tool_call: inspect tool output before it re-enters the model contextoutput: inspect the final response before it leaves the agentagent_shutdown: evaluate end-of-session conditions for logging and audit
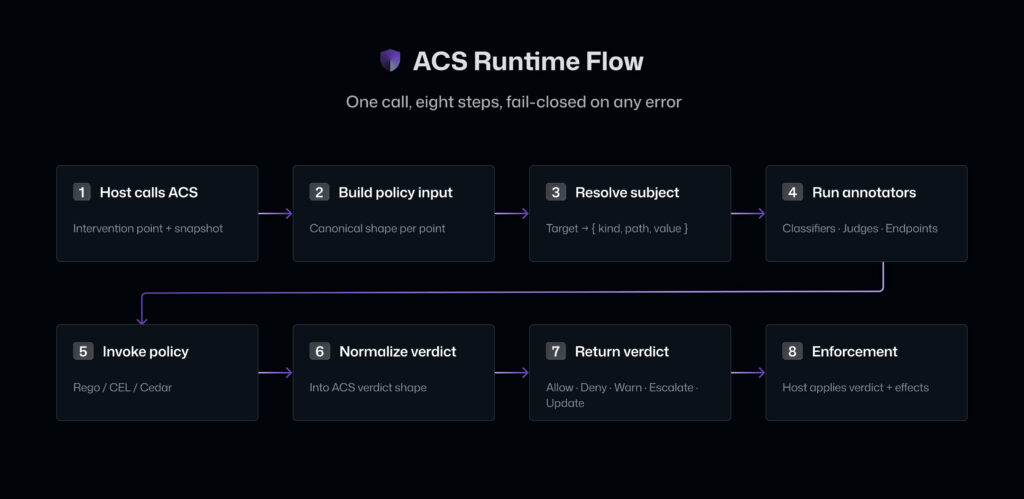
Each call to ACS stands on its own: The host runtime passes the current snapshot, and ACS shapes the canonical input, runs configured evidence providers, invokes the policy engine, and returns a normalized verdict. Anything the policy needs to know about the session, including prior tool calls, accumulated sensitivity, approval state, user history, lives in the snapshot the host passes in.
The canonical policy input
At each intervention point, ACS turns the current agent context into a standard policy input. This input is the bridge between the agent runtime and the policy engine.
{
"intervention_point": "pre_tool_call",
"policy_target": { "kind": "tool_args", "path": "...", "value": { ... } },
"snapshot": { /* full host context */ },
"annotations": { /* results from classifiers, LLM judges, etc. */ },
"tool": { "name": "...", "clearance": [...], "security_labels": [...] }
}
A policy input includes a few key pieces:
intervention_pointtells the policy engine where in the agent lifecycle the check is happening. For example,pre_tool_callmeans ACS is evaluating a tool call before the tool runs.policy_targetis the specific thing being evaluated. In a tool call, this might be the tool arguments. In an output check, it might be the final response.snapshotis the broader context provided by the host runtime. This can include the actor, roles, conversation state, prior tool calls, data sensitivity, approval status, or anything else the policy may need.annotationscontains evidence collected before the policy runs, such as results from classifiers, DLP systems, LLM judges, or external services.toolincludes tool metadata, like the tool name, clearance level, and security labels, when the intervention point involves a tool.
A worked example: The same manifest across two SDKs
Consider an email agent that must not send messages to external recipients. A single manifest binds one Rego policy to the pre_tool_call intervention point and declares the tool the policy reasons about:
agent_control_specification_version: "0.3.1-beta"
metadata:
name: "email-agent"
policies:
email_policy:
type: rego
bundle: ./policy
query: data.email_agent.verdict
intervention_points:
pre_tool_call:
policy_target: "$.tool_call.args"
policy_target_kind: tool_args
tool_name_from: "$.tool_call.name"
policy:
id: email_policy
tools:
send_email:
type: Tool
id: send_email
clearance: internal
The Rego policy reads the projected tool arguments and denies external recipients:
A Python host loads the manifest with AgentControl.from_path and evaluates the pre-tool snapshot:
from agent_control_specification import AgentControl, InterventionPoint
control = AgentControl.from_path("manifest.yaml")
result = await control.evaluate_intervention_point(
InterventionPoint.PRE_TOOL_CALL,
{"tool_call": {"id": "t1", "name": "send_email",
"args": {"to": "[email protected]"}}},
)
assert result.verdict.decision.value == "deny"
A Node host takes the same manifest and the same snapshot, and reaches the same verdict:
const { AgentControl, InterventionPoint } = require("agent-control-specification");
const control = AgentControl.fromPath("manifest.yaml");
const result = await control.evaluateInterventionPoint(
InterventionPoint.PreToolCall,
{ tool_call: { id: "t1", name: "send_email",
args: { to: "[email protected]" } } },
);
// result.verdict.decision === "deny"
Both SDKs load the same native core and evaluate the same Rego bundle. Cross-SDK conformance fixtures assert that the .NET and Rust SDKs return identical verdicts for the same snapshots, so the controls follow the agent when it moves from a Python service to a Node sidecar, or from a local script to a hosted runtime.
Get started
The repository is at github.com/microsoft/agent-governance-toolkit.
The documentation includes a quickstart guide for common frameworks and languages. The project is MIT-licensed and developed in the open. The spec is the source of truth. SDK behavior that diverges from it is a bug. Issues, RFCs, and adapter contributions are welcome.
Agent frameworks will change. Policy engines will evolve. Governance requirements will increase. The enforcement contract shouldn’t have to be rewritten each time.
Relationship with Agent Framework Toolkit
ACS is a controls layer, not an agent framework. It does not orchestrate the loop, choose tools, or manage memory. Those responsibilities belong to the host and to the framework the agent is built on, including the Microsoft Agent Framework, whose objects can be guarded directly through the ACS SDK adapters. ACS plugs into the moderation points each framework already exposes and supplies the pieces above them that no framework provides on its own: the canonical input shape, the evidence pipeline, the normalized verdict, and the fail-closed enforcement contract. The effect is that a team can pick or change agent frameworks without rewriting its policy surface, and a security team gets one place to author, version, and audit controls regardless of the runtime underneath.
Relationship with Agent Governance Toolkit
Agent Governance Toolkit (AGT) is the Microsoft-signed runtime that bundles policy enforcement, identity, sandboxing, and audit for production agents. The next version of AGT adopts ACS as its policy language, so existing AGT users gain the eight intervention points, the canonical policy input, Rego-based decisioning, and the framework adapters that ACS provides, while keeping AGT’s identity, sandboxing, and audit guarantees.
“The agent ecosystem needs an open standard for guardrails the same way it needs open standards for tool protocols and model interfaces. CrewAI has always leaned on open primitives, agents, and tasks declared in YAML, an OSS core anyone can extend, and guardrails should follow the same pattern: declarative, portable, not tied to any single vendor. That’s the direction Agent Control Specification is going, and it’s why we support it.”
Acknowledgements
PM team: Mehrnoosh Sameki, Mike Shi
Eng team: Mohamed Elmargawi, Mohammad Abouomar, Liam Crumm, Apoorv Jindal, Roni Burd
Design: Sooyeon Hwang
Business development: Ilvens Jean